

Search engines work by interpreting a user query, crawling web pages, indexing discovered content, ranking eligible URLs, and serving the best results on a SERP. AI and NLP help search engines understand meaning, intent, entities, and relationships so users receive relevant web pages, snippets, images, videos, local results, shopping results, or AI-generated answers.
What Is a Search Engine?
A search engine is an information retrieval system that finds, organizes, and returns internet content for a user’s query. It connects users to web pages, images, videos, local listings, products, and answers through crawled, indexed, and ranked results.
How is a search engine different from a browser?
A browser is software that opens websites. Chrome, Firefox, Safari, and Edge load URLs, display web pages, and execute page resources. A search engine retrieves ranked information before the user chooses a result. The browser is the access tool. The search engine is the retrieval system. A website is the destination.
What Happens When You Enter a Search Query?
User input becomes a processing signal when keywords, phrases, or natural language are parsed into machine-readable meaning. The search engine identifies entities, detects search intent, applies context such as language and location, and prepares retrieval instructions before ranking begins.
How do search engines classify query intent?
Search engines classify query intent by matching the query to a user goal. Informational intent seeks knowledge. Navigational intent seeks a known website or brand. Commercial investigation intent compares options before action. Transactional intent signals purchase, booking, download, signup, or another completion event.
Intent category controls result composition. Informational queries trigger guides, snippets, images, videos, or People Also Ask results. Navigational queries prioritize official destinations. Commercial queries surface comparisons, reviews, and product pages. Transactional queries emphasize product listings, service pages, local packs, and shopping elements.
How do AI and NLP help interpret queries?
AI improves query interpretation by detecting patterns across language, behavior, and document relationships. NLP converts query text into entities, attributes, values, and relationships. Entity recognition identifies the subject. Relationship extraction identifies how the subject connects to another concept. Intent matching identifies the expected outcome.
Complex queries need semantic resolution. The query “best phone for video recording under 500 dollars” contains a product entity, use-case attribute, price constraint, and comparison intent. Semantic search connects those elements to indexed documents that satisfy the complete meaning, not only the exact words.
What Are the Main Stages of How Search Engines Work?
Search operations move through 5 connected stages: query understanding, crawling, indexing, ranking, and SERP serving. Each stage transforms raw input, discovered URLs, stored signals, evaluation scores, and display formats into a complete retrieval workflow for the user’s online search request.
Search Engine Workflow
The full search engine workflow converts a query into a visible result set through 5 process states: input, discovery, storage, ordering, and output.
Query understanding interprets the user’s need
Query understanding turns user input into structured search purpose. NLP identifies the topic, modifier, constraint, and expected answer form. Intent defines the retrieval direction. Context narrows ambiguity. The output is a machine-readable need that guides document matching.
Crawling discovers URLs and content
Crawling uses crawlers, bots, or spiders to locate URLs through hyperlinks, sitemap entries, and known URL records. Fetching retrieves page resources. Recrawling refreshes stored knowledge when content changes. The output is a discovered document eligible for analysis.
Indexing stores and organizes content
Indexing analyzes discovered content and stores its signals inside a searchable database. The index records text, links, media references, metadata, canonical signals, and structured data. Cataloging organizes these signals so retrieval systems can match documents to future queries.
Ranking orders indexed pages
Ranking applies a search engine algorithm to eligible indexed pages. The algorithm compares relevance, authority, quality, freshness, location, device fit, and result usefulness. Ordering places stronger matches above weaker matches. The output is a ranked list for a specific query context.
SERP serving displays results and features
SERP serving converts the ranked list into visible search features. Organic results, AI Overviews, featured snippets, image packs, video results, news modules, local packs, and shopping units appear when the query context supports those formats. The output is the search results page.
How Does Crawling Work?
Crawling discovers accessible URLs by sending web crawlers to fetch page resources, inspect links, record changes, and schedule recrawls. Web crawling creates the document supply that indexing systems analyze before pages qualify for retrieval, ranking, SERP placement, and user visibility.
Crawlers, Bots, Spiders, and Robots
Crawlers, bots, spiders, and robots are crawler-agent labels for automated search engine software. A crawler identifies URLs. A bot performs automated retrieval tasks. A spider follows web paths between documents. A robot follows protocol rules such as robots.txt directives.
Search engine bots use user-agent names to identify themselves to servers. Googlebot, Bingbot, DuckDuckBot, and YandexBot represent crawler systems from different search engines. Server logs record these user agents when they request URLs.
Crawlers Discover URLs
Crawlers discover URLs through hyperlinks, internal links, external links, XML sitemaps, RSS feeds, known URL databases, and submitted URLs. Internal links expose pages inside one website. External links expose pages from other websites. Sitemaps provide a structured URL list for discovery.
How do crawlers find new and updated pages?
Crawlers find new pages through fresh links, sitemap entries, URL submissions, and newly detected references across the web graph. Crawlers detect updated pages through changed HTML, modified metadata, new links, altered content blocks, updated media references, and lastmod sitemap values.
Recrawling frequency depends on URL importance, change rate, server reliability, historical update patterns, and crawl demand. Freshness signals help search engines decide which documents need renewed processing before the index reflects current content.
How Can Website Owners Control Crawling?
Using robots.txt for access rules, XML sitemaps for discovery support, crawl budget optimization for priority handling, URL parameter controls for duplicate paths, redirects for URL movement, and crawl-error reports for access diagnostics.
How does robots.txt guide crawlers?
Robots.txt is a crawl-instruction file placed in a website’s root directory, such as /robots.txt. It gives compliant search engine bots path-level instructions before they request deeper URLs.
Robots.txt controls crawling, not indexing. A blocked URL remains eligible for limited index appearance when external links or other references reveal it. Index removal requires indexing directives, deletion signals, canonical handling, or removal tools.
Sitemaps & Crawlers
XML sitemaps give crawlers a machine-readable list of important URLs. A sitemap entry can include the canonical URL, last modification date, image references, video references, and alternate-language annotations.
lastmod identifies the last meaningful content update. Accurate lastmod values help crawlers prioritize refreshed URLs. False update dates reduce signal reliability. Sitemap inclusion improves discovery support, but it does not guarantee indexing, ranking, or traffic.
Crawl Budget for Large Websites
Crawl budget is the practical limit of URLs a search engine bot crawls from a site within a crawl cycle. Large websites face crawl-budget pressure because faceted navigation, duplicate paths, expired pages, internal search URLs, and parameter variants create unnecessary URL volume.
Crawl budget has 2 core components: crawl demand and crawl capacity. Crawl demand reflects URL importance, popularity, freshness, and update frequency. Crawl capacity reflects server speed, error rate, timeout behavior, and response stability.
HTTP Status Codes
HTTP status codes tell crawlers how a URL responds during a request. Each code changes crawl behavior, access interpretation, and follow-up processing.
| Status Code | Meaning | Crawl Interpretation |
| 200 | OK | URL is accessible and ready for processing |
| 301 | Permanent redirect | URL has moved permanently to another location |
| 302 | Temporary redirect | URL has moved temporarily to another location |
| 404 | Not found | URL is missing or unavailable at that path |
| 410 | Gone | URL has been intentionally removed |
| 500 | Internal server error | Server failed to complete the request |
| 503 | Service unavailable | Server is temporarily unavailable or overloaded |
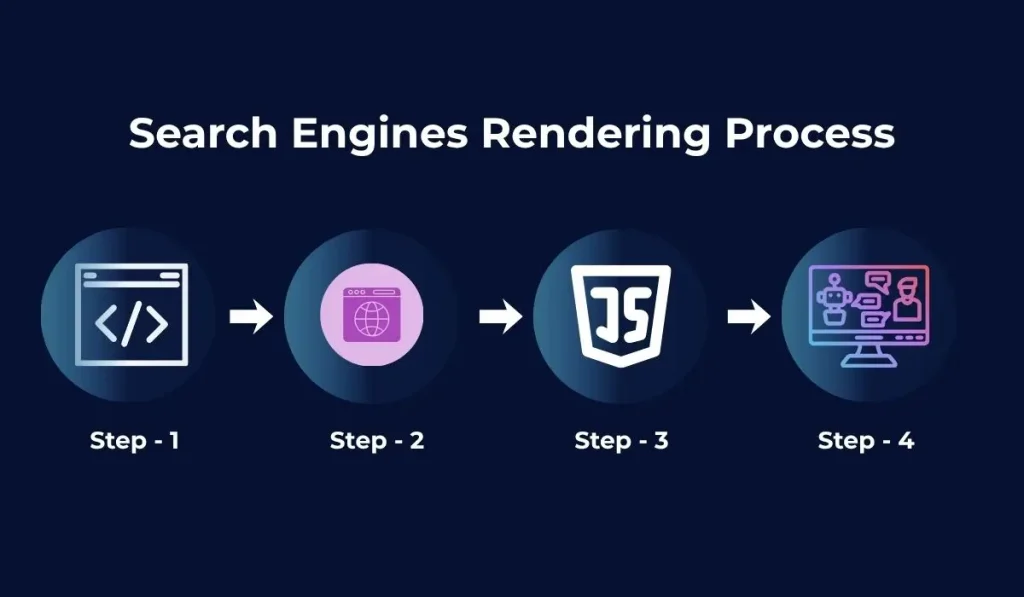
How Do Search Engines Render and Process Web Pages?
Search engines render and process web pages by parsing HTML, building the DOM, executing JavaScript, applying CSS, detecting blocked resources, and extracting visible content, links, metadata, and structure for indexing and retrieval readiness.
HTML Parsing help’s Search Engines
HTML parsing reads page code and separates structural elements from visible content. The title tag identifies the document’s primary label. Headings organize topic hierarchy. Body text supplies the main content. Internal links define page relationships. External links identify referenced sources.
Search engines use HTML elements as relevance signals because each element carries a different document role. A title tag gives the strongest page-level label. H1 and H2 headings define section scope. Anchor text describes linked destinations. Body copy provides entity, attribute, and value coverage.
JavaScript Rendering
JavaScript rendering affects processing when important content appears only after scripts run. Client-side rendering builds visible page content in the browser after the initial HTML response. Search engines need rendered HTML to access script-generated text, links, product data, filters, reviews, and navigation elements.
Rendering dependency creates risk when scripts fail, load slowly, require user interaction, or hide content behind app states. Server-side rendering and static HTML reduce this risk because the main content is available in the first response. Hydration supports interactivity after the core document is already visible.
Blocked Resources Rendering
Blocked resources are CSS files, JavaScript files, images, fonts, or API endpoints that crawlers cannot request. Robots.txt rules, authentication barriers, server errors, CDN restrictions, and firewall settings can block these resources.
Blocked CSS reduces layout interpretation. Blocked JavaScript prevents script-generated content from appearing in the rendered page. Blocked images remove visual context. Blocked API responses can hide product listings, reviews, prices, availability, and faceted navigation data.
Rendering accuracy depends on resource access. A crawler that receives incomplete resources sees a different page from a user. That difference weakens content extraction, link discovery, mobile layout evaluation, and page-quality interpretation.
Server and Security Signals Processing
HTTPS delivers pages through an encrypted connection. TLS establishes the encryption layer. HSTS instructs browsers to use secure connections by default. Mixed content occurs when a secure page loads insecure HTTP resources.
Secure delivery supports stable page access because crawlers can request resources without unsafe transport conflicts. Mixed content can block scripts, images, fonts, or embedded assets. Broken TLS certificates interrupt access. HSTS misconfiguration can force failed secure requests.
What Is Indexing in Search Engines?
Once rendering exposes a page’s machine-readable document signals, indexing analyzes, maps, stores, and catalogs those signals inside a search index. This database gives each eligible URL retrieval eligibility, so ranking systems can select it for relevant future search queries later.
Search Index
A search index is the structured retrieval layer that maps queries to eligible documents. It works like a massive lookup system, not a simple folder of saved pages. Each indexed URL receives a document record that search systems can retrieve, compare, score, and return.
An indexed page has passed minimum processing and eligibility checks. A non-indexed page lacks retrieval status for normal search results. Index status separates pages that search engines know about from pages that search engines can serve.
Why are Crawled pages not Always Indexed?
Crawled pages fail indexing when they do not meet eligibility, quality, uniqueness, or access requirements. Crawling proves discovery. Indexing requires enough value, clarity, and permission for search inclusion.
Indexing systems prioritize documents that add unique search value. A page with weak content, duplicate purpose, blocked evaluation, or conflicting instructions remains outside the main searchable set.
How Can Website Owners Control Indexing?
Website owners control indexing with robots meta directives, X-Robots-Tag headers, canonical tags, metadata, structured data, Google Search Console, and CMS settings that define inclusion, exclusion, preferred URLs, diagnostics, and entity context for search systems reliably.
Robots Meta Directives
Robots meta directives are HTML-level instructions placed inside the <head> section of a page. They tell search engine crawlers how the page and its links should be treated after the page is accessed.
A basic robots meta instruction uses this format: <meta name="robots" content="noindex, follow">
The name="robots" value targets all compliant search engines. A bot-specific value, such as name="googlebot", targets one crawler. Directive conflicts create weak signals. A page with noindex in one location and index in another location sends inconsistent instructions.
The X-Robots-Tag
X-Robots-Tag is an HTTP-header directive that controls indexing outside the visible HTML document. It applies to HTML pages, PDFs, images, videos, documents, and other non-HTML files. A server can return this header:
X-Robots-Tag: noindex, nofollow
Header-level control is useful when the file has no editable HTML <head>. Server configuration, CDN rules, and application middleware can all deliver the X-Robots-Tag response.
Canonicalization Guide Index
Canonicalization guides search engines toward the preferred URL when duplicate or near-duplicate URLs exist. The canonical tag appears in HTML as rel="canonical" and points from a duplicate version to the representative version.
A canonical instruction uses this format: <link rel="canonical" href="https://example.com/preferred-url/">
Canonical signals work best when internal links, sitemap URLs, redirects, hreflang annotations, and structured data reference the same preferred URL. Mixed signals weaken index selection. A page that canonicals to URL A, appears in the sitemap as URL B, and receives internal links as URL C creates unnecessary canonical ambiguity.
Metadata and Structured Data
Metadata describes page-level context. The title tag names the document. The meta description summarizes the page for result interpretation. Language annotations clarify audience targeting. Robots directives provide search instructions.
Structured data declares entities and relationships in machine-readable form. JSON-LD is the preferred format for schema markup because it separates entity declarations from visible HTML layout. Structured data does not replace visible content. It supports indexing by confirming the entities, attributes, values, and relationships already present on the page.
How Do Search Engines Rank URLs?
Index controls define eligible documents, ranking algorithms compare indexed pages against query context, score relevance, usefulness, quality, authority, freshness, and location fit, then place best matches into result positions that shape SERP visibility and user selection behavior at scale.
The Aim of a Search Engine Algorithm
A search engine algorithm is a retrieval formula that evaluates indexed documents and produces useful results for a user query. Its aim is query satisfaction. The algorithm connects search intent to documents that answer the task with the highest measurable fit.
Algorithmic evaluation uses multiple signal groups. Text signals show topical match. Link signals show reference strength. Freshness signals show update relevance. Location signals support geographic fit. Quality signals separate complete answers from shallow documents.
Algorithms Evaluate Relevance
Relevance measures how closely a document matches the meaning of a query. Search intent defines the user’s goal. Content relevance measures direct topical coverage. Semantic relevance measures entity, attribute, value, and relationship alignment.
A relevant page covers the primary entity, required sub-entities, necessary attributes, and expected answer format. For the query “how search engines work,” relevance requires crawling, indexing, ranking, query understanding, SERP output, algorithms, and search result formats. Missing core entities weaken topical fit.
Algorithms Evaluate Authority
Authority measures the strength of external and internal references connected to a page, domain, business, or entity. Backlinks act as third-party references. Internal links pass contextual importance inside the site. Citations validate business information. Prominence reflects recognition across trusted sources.
PageRank represents a classic link-analysis model. It evaluates link quantity and link quality to estimate page importance. Modern authority evaluation includes more than PageRank, but the same relationship remains: trusted references strengthen confidence in a document, source, or local entity.
Algorithms Evaluate Quality
Quality measures whether content satisfies a query with complete, original, useful, and trustworthy information. Helpful content answers the task directly. Thin content lacks depth. Duplicate content repeats existing material. Low-quality content uses manipulation, weak sourcing, or irrelevant expansion.
Quality evaluation checks page purpose. A medical page needs safety, accuracy, and source transparency. A product page needs specifications, pricing, availability, reviews, and comparison support. A tutorial needs steps, requirements, examples, and error handling.
RankBrain Ranking
RankBrain is Google’s machine-learning system for query interpretation and result matching. It helps process unfamiliar, ambiguous, long-tail, and conversational queries by connecting language patterns to documents with matching meaning.
RankBrain improves ranking when exact keyword matching is insufficient. It interprets query relationships, identifies likely intent, and supports matching between differently worded queries and relevant documents. A page can rank without repeating every query word when its entities and relationships satisfy the same meaning.
Engagement Metrics
Engagement metrics describe how users interact with search results and landing pages. Clicks measure result selection. Time on page measures visit duration. Bounce rate measures single-page sessions. Pogo-sticking describes a user returning from one result to the SERP and selecting another result.
Engagement data requires analytical caution. Correlation means strong-ranking pages and strong engagement appear together. Causation means engagement directly produces ranking movement. Correlation alone does not prove direct causation.
Which Technical, Content, and UX Factors Influence Search Performance?
Search performance depends on technical access, content satisfaction, user experience, trust signals, and freshness. Page speed, Core Web Vitals, mobile-friendliness, HTTPS, topical coverage, authority, and quality help search systems choose stable, useful results across query contexts consistently.
Content Relevance
Content relevance depends on how completely a page satisfies the specific search intent behind a query. Topic coverage must include the primary entity, supporting sub-entities, required attributes, expected examples, and the answer format that the SERP already rewards.
A relevant page for an informational query provides definitions, process steps, comparisons, examples, and troubleshooting paths. A relevant page for a commercial query provides specifications, alternatives, prices, reviews, and decision criteria. Query context determines the required content depth.
Page Speed in Search Performance
Page speed affects search performance through server response, loading speed, interactivity, and layout stability. TTFB measures how fast the server starts responding. LCP measures main content loading. INP measures interaction responsiveness. CLS measures unexpected layout movement.
Slow pages create delayed rendering, weaker user satisfaction, and inefficient resource fetching. Heavy JavaScript, uncompressed images, render-blocking CSS, excessive third-party scripts, slow hosting, and poor caching reduce page-speed performance.
Mobile-Friendliness in Search Performance
Mobile-friendliness measures whether a page works clearly on mobile devices. Responsive design adapts layout to screen size. Mobile UX controls readability, tap accuracy, viewport fit, menu access, form usability, and content visibility.
A mobile-friendly page uses readable font sizes, visible navigation, compressed media, accessible buttons, stable layouts, and content that fits without horizontal scrolling. A weak mobile page creates friction before the user can complete the search task.
Security Protocols
Security protocols protect access between the user, browser, server, and page resources. HTTPS encrypts page delivery. TLS authenticates and secures the connection. HSTS enforces secure requests. Mixed content weakens trust because insecure HTTP assets load inside secure pages.
Security affects search performance through access reliability and user confidence. Invalid certificates block visits. Mixed scripts fail or create browser warnings. Insecure forms expose user data. Broken secure resources reduce page functionality.
A secure page keeps HTML, images, scripts, fonts, forms, analytics, and embedded assets on HTTPS. This consistency prevents transport warnings, protects data exchange, and supports stable retrieval, rendering, and interaction across browsers and devices.
How Do Search Engines Serve Results on a SERP?
SERP serving converts selected documents, media, entities, and answer sources into visible result formats. The search engine results page displays organic URLs, AI Overviews, snippets, images, videos, news, local packs, and shopping modules by query intent.
Organic Results
Organic results are non-paid URLs selected by the ranking algorithm for a specific search query. Each organic listing usually contains a title link, visible URL path, snippet text, sitelinks, date information, and sometimes rich-result enhancements.
Organic placement depends on algorithmic relevance, not ad payment. A result in position 1 receives the highest organic placement for that query context. Lower positions receive less visual priority because the SERP orders non-paid results from strongest match to weaker match.
AI Overviews
AI Overviews are AI-generated summaries displayed for queries where a synthesized answer helps the user understand the topic faster. They combine selected source material, generated explanation, and source citations inside one answer area.
An AI Overview uses cited pages as supporting sources. Source selection depends on content clarity, topical fit, factual support, and answer usefulness. A page that states entities, attributes, values, and relationships clearly gives AI systems stronger extraction points.
Featured Snippets
A featured snippet is an extractive answer pulled from a webpage and displayed above or near standard organic results. It answers the query directly through a paragraph, list, table, definition, step sequence, or short comparison.
Featured snippets favor content with clear answer blocks. A definition query needs a compact definition. A process query needs ordered steps. A comparison query needs a table. A “what is” query needs a direct sentence with the entity first.
Image, Video, and News Results
Image results retrieve visual assets using filenames, alt text, surrounding text, captions, page topic, image quality, and structured data. A query such as “search engine crawling diagram” needs visual explanation, so image modules can appear.
Video results retrieve video assets using titles, descriptions, chapters, transcripts, thumbnails, engagement signals, and platform metadata. YouTube results dominate many video SERPs because YouTube supplies structured video data and user interaction signals.
News results retrieve timely articles using publisher relevance, freshness, topical authority, timestamps, headlines, and story clustering. A current search-engine update query needs recent reporting, while an evergreen definition query needs stable explanatory content.
Local and Shopping Results
Local results connect searches to businesses and places. They use location data, business categories, map relevance, reviews, opening hours, service areas, photos, citations, and proximity signals to build a local pack or map-based result.
Shopping results connect searches to products. They use product titles, prices, availability, merchant data, reviews, images, shipping details, variants, and structured product feeds to support commercial comparison.
How Do AI, NLP, and Knowledge Graphs Change Search Engines?
AI, NLP, and knowledge graphs change search engines by converting text into entities, relationships, and generated answers. Semantic search moves beyond keyword matching toward meaning extraction, source synthesis, and entity-based result understanding for users.
AI Improve Search Engines
AI improves search engines by handling complex queries that contain multiple constraints, implied meanings, comparisons, and incomplete wording. It detects patterns across query behavior, document language, source consistency, and result satisfaction.
AI supports answer generation when a query needs synthesis instead of a single extracted line. It can combine definitions, steps, comparisons, and source-backed facts into a compact response format. This changes search from document retrieval alone into document retrieval plus answer construction.
NLP Process Natural Language Queries
NLP processes natural language queries by breaking text into searchable language units. Tokenization separates words and phrases. Part-of-speech tagging identifies nouns, verbs, adjectives, and modifiers. Named entity recognition identifies people, products, brands, places, concepts, and systems.
NLP connects query terms through relationships. Dependency parsing shows which words modify other words. Entity linking connects a phrase to a known entity. Semantic matching connects differently worded expressions that share the same meaning.
How does Semantic Search use Entities and Attributes?
Semantic search uses entities, attributes, values, and relationships to understand meaning. An entity is a thing or concept. An attribute is a property of that entity. A value is the specific data attached to the attribute. A relationship connects 2 entities.
Semantic search strengthens retrieval because it recognizes meaning beyond exact wording. “How Google stores pages,” “what is indexing,” and “how search engines organize URLs” share related entity structures. The wording changes, but the underlying concept remains connected.
How do knowledge graphs improve search understanding?
A knowledge graph is a connected database of entities, attributes, facts, and relationships. It helps search systems understand that Google is a search engine, Googlebot is a crawler, crawling precedes indexing, and indexing supports retrieval.
Knowledge graphs improve disambiguation. The word “index” can refer to a search database, a book section, a stock market measure, or a programming structure. Entity associations clarify the intended meaning when surrounding terms include crawling, Googlebot, URLs, ranking, and SERP.
How Does Google Search Work Step by Step?
Google Search applies a fully automated system where Googlebot discovers pages, the Google Index stores eligible content, Google algorithms rank results, and Google SERP features display answers. Google Search Console gives verified site owners diagnostic visibility into that process directly.
Googlebot Discover Pages
Googlebot discovers pages by adding URLs to a crawl queue from links, XML sitemaps, previous crawl records, redirects, and submitted URL signals. Before requesting a URL, Googlebot checks crawl permission rules and determines whether the host can handle the request.
Googlebot does not treat all discovered URLs equally. URL importance, update frequency, host reliability, internal link depth, sitemap consistency, and duplication patterns influence crawl priority.
Google Indexed Pages
Google Index stores eligible pages after Google processes the document, evaluates signals, and selects a representative URL for search. Google analyzes text, links, images, metadata, structured data, language, canonical hints, and duplicate clusters before index inclusion.
Google-selected canonical is the URL Google chooses as the main version of a document. User-declared canonical is the URL the site owner recommends. Index selection works best when canonical tags, internal links, sitemap URLs, redirects, and hreflang references point to the same version.
Google Rank Pages
Google Algorithm ranks pages by matching indexed documents to the query’s meaning, task, and context. Google’s ranking systems evaluate relevance, quality, usability, source signals, location fit, language fit, freshness needs, and result-type suitability.
RankBrain supports Google’s handling of unfamiliar and ambiguous queries. It strengthens matching when query wording differs from document wording. Relevance connects the page to the query. Quality evaluates content usefulness. Authority evaluates source confidence. Usability evaluates whether the result can satisfy the user without avoidable friction.
Google Display Results
Google SERP displays ranked links and enhanced features based on the query’s dominant intent. A simple factual query can trigger a direct answer. A visual query can trigger images. A local query can trigger a map pack. A commercial query can trigger shopping elements.
Google display systems choose layout based on usefulness, not page-owner preference. Structured content improves eligibility for enhanced display, but Google controls final SERP presentation.
How do Google understand pages?
Website owners help Google understand pages by making technical signals, content signals, and entity signals consistent. Google Search Console shows URL-level evidence. Structured data declares machine-readable entities. Internal links define page relationships. Metadata labels page purpose. Sitemaps submit important canonical URLs.
Implementation requires signal alignment.
| Website Signal | Google Understanding Supported |
| Clear title tag | Primary page topic |
| Descriptive headings | Section-level meaning |
| Internal anchor text | Destination context |
| JSON-LD schema | Entity type and attributes |
| XML sitemap | Canonical URL discovery |
| GSC URL Inspection | Crawl, index, and canonical diagnostics |
| Consistent canonical tags | Preferred URL selection |
Google understands pages faster when the HTML, metadata, schema, sitemap, internal links, and visible body content describe the same entity with the same intent. Conflicting signals force Google to infer the page's purpose instead of confirming it.
How Do Search Engines Make Money?
Search engines make money by selling paid visibility through search ads, shopping ads, sponsored listings, and commercial placements. Organic results remain algorithmic, while ad systems use advertiser bids, targeting, relevance, and auction rules to display paid results beside search results.
Ads on SERPs
Paid ads appear on SERPs through sponsored placements above, below, or beside unpaid listings. Search ads usually match keyword intent, landing page relevance, advertiser targeting, bid amount, quality score, location, device, and competition level.
Ad labels separate sponsored results from unpaid listings. A paid search result can include a headline, display URL, description, sitelinks, callouts, phone number, location asset, image asset, price extension, or promotion detail.
Shopping ads use product data instead of standard text-ad structure. They display product images, names, prices, merchants, ratings, delivery information, and promotional details when the query shows commercial or transactional intent.
Paying on Organic Rankings
Paying for ads does not improve organic rankings. Paid systems and organic systems use separate selection processes. Ads buy sponsored visibility. Organic rankings depend on relevance, quality, authority, usefulness, accessibility, and search intent satisfaction.
Ad campaigns can increase brand exposure, query demand, and user familiarity, but those effects are indirect marketing outcomes. They do not change the organic ranking algorithm directly.
How Does Local Search Work?
Commercial SERPs handle product demand; local search handles nearby business discovery. Local search ranks businesses and places by relevance, distance, prominence, reviews, citations, organic ranking, and engagement signals to connect users with map results, calls, directions, bookings, and visits.
Relevance, Distance, and Prominence
Relevance, distance, and prominence are the 3 core local ranking signals that connect a local query to a business entity. Relevance measures business-query match. Distance measures geographic proximity. Prominence measures real-world and online recognition.
A “dentist near me” query needs a dental business category, service-area match, reachable location, strong profile completeness, and enough prominence to compete against nearby alternatives. Local ranking combines map context with business-entity confidence.
Reviews and Citations
Reviews provide user-generated evidence about a business. Ratings quantify satisfaction. Review text adds service attributes, product details, staff mentions, location references, and problem-solution language.
Citations are web references to a business’s NAP: name, address, and phone number. Consistent NAP data across business directories, local platforms, maps, social profiles, and industry listings validates the local entity.
Organic Ranking Influence
Organic ranking supports local search because local algorithms also evaluate website authority, content quality, internal structure, and backlink signals. A strong website gives the business entity more evidence beyond its map listing.
Local landing pages strengthen geographic relevance. A service page can connect the business to a city, neighborhood, service category, opening hours, pricing context, testimonials, FAQs, and driving-distance details. These page-level signals support local SERP understanding.
Local Engagement
Local engagement describes how users interact with a business entity in local search surfaces. Common actions include profile views, direction requests, phone calls, website clicks, booking clicks, photo views, question submissions, review interactions, and saved-place actions.
Engagement signals require cautious interpretation. Strong interaction patterns show that users find a listing useful for a local task. Weak interaction patterns reveal possible mismatch in category, distance, reviews, photos, hours, service details, or offer clarity.
What Is the Complete Search Engine Optimization Checklist?
Local visibility proves search systems reward clear signals; a complete SEO checklist converts that logic into action across crawlability, indexability, ranking readiness, and SERP visibility by verifying access, content value, technical stability, entity clarity, structured data, and extraction readiness.
Crawling checklist
- Verify robots.txt access: Important URLs are not blocked by unnecessary Disallow rules.
- Submit XML sitemaps: Canonical, indexable, 200-status URLs appear in the submitted sitemap.
- Strengthen internal links: Priority pages receive crawlable HTML links from relevant hub pages.
- Reduce crawl waste: Parameter URLs, duplicate paths, faceted variants, and low-value archives are controlled.
- Fix redirect chains: Old URLs redirect to final destinations in 1 hop.
- Resolve 4xx errors: Broken internal links, deleted assets, and missing destination pages are corrected.
- Stabilize 5xx responses: Server errors, timeouts, and overload events are removed from crawl paths.
Rendering and security checklist
- Test rendered HTML: Main content, navigation, links, products, reviews, and CTAs appear after rendering.
- Audit JavaScript dependency: Critical content loads without fragile user actions, delayed API calls, or blocked scripts.
- Unblock required resources: CSS, JS, fonts, images, and API endpoints are accessible to crawlers.
- Validate HTTPS coverage: Pages, assets, forms, scripts, and embeds load through secure URLs.
- Confirm TLS validity: Certificates are active, trusted, and correctly configured.
- Enforce HSTS safely: Secure requests work across the whole domain before strict enforcement.
- Remove mixed content: HTTP assets are replaced with HTTPS versions.
Indexing checklist
- Inspect noindex usage: Only intentionally excluded pages carry noindex directives.
- Align canonical tags: Canonical tags match internal links, sitemap URLs, redirects, and preferred URL versions.
- Check GSC index status: Important URLs show crawlable, indexable, canonical-consistent status.
- Improve thin content: Low-depth pages gain unique entities, attributes, examples, and search-task coverage.
- Consolidate duplicate content: Similar URLs are merged, canonicalized, redirected, or rewritten by intent.
- Validate structured data: JSON-LD uses correct schema types, required properties, and visible content alignment.
- Remove index bloat: Tag archives, filter URLs, search-result pages, and weak taxonomies are excluded or consolidated.
Ranking checklist
- Match search intent: Each page satisfies the dominant informational, navigational, commercial, or transactional task.
- Complete EAV coverage: Primary entities include required attributes, values, relationships, and examples.
- Strengthen internal links: Hub pages, spoke pages, breadcrumbs, and contextual anchors reinforce topical relationships.
- Earn relevant backlinks: Trusted sources reference the page, brand, service, location, or topical asset.
- Improve Core Web Vitals: LCP, INP, and CLS meet stable user-experience standards.
- Optimize mobile UX: Layout, navigation, forms, media, and tap targets work cleanly on mobile devices.
- Update freshness signals: Time-sensitive pages include current data, screenshots, citations, prices, or version details.
SERP visibility checklist
- Write extractive answers: Each major section provides a concise answer block that search systems can lift.
- Structure snippet targets: Definitions, lists, tables, steps, and comparisons match featured-snippet formats.
- Support AI Overview inclusion: Facts are clear, source-backed, entity-rich, and easy to summarize.
- Optimize image assets: Filenames, alt text, captions, and surrounding text describe the subject and context.
- Optimize video assets: Titles, descriptions, transcripts, chapters, thumbnails, and schema support video retrieval.
- Add FAQ coverage: PAA-style questions answer unresolved micro-intents without bloating the main flow.
- Validate rich-result eligibility: Structured data passes testing and matches visible page content.
How Should You Move From Learning to Implementation?
Supporting assets clarify the system; implementation turns that knowledge into measurable SEO work. Website owners should audit technical access, validate indexability, improve semantic content coverage, build topical maps, create content briefs, and measure AI search visibility across priority queries.
Request a Semantic Content Audit
Request a semantic content audit when indexed pages rank poorly, lose impressions, fail snippet extraction, or miss AI citation opportunities. The audit should compare entities, attributes, values, relationships, query intent, heading coverage, internal links, and topical authority against the live SERP.
A semantic audit identifies content completeness problems. Missing entities weaken meaning. Missing attributes weaken usefulness. Missing relationships weaken topical clarity. Poor intent alignment creates ranking friction even when the page is technically accessible and indexed.
Build a Topical Map
Build a topical map when one article cannot cover the full macro context of a subject. A topical map organizes hub pages, spoke pages, internal links, anchor text, supporting entities, and search intents into a content network.
A hub-and-spoke structure strengthens site-wide authority by assigning each page a clear semantic role. The hub covers the macro entity. Spoke pages cover micro-intents. Internal links connect parent topics, child topics, supporting definitions, comparisons, checklists, and conversion pages.
The Next Step
The next step is a scoped SEO consultation, website audit, checklist review, or content brief based on the weakest search-process layer. Crawlability issues need technical diagnosis. Indexability issues need directive and canonical review. Ranking issues need semantic content improvement. Site-wide gaps need topical-map planning.
A strong implementation plan should identify 4 items: the affected URL set, the failed search stage, the evidence source, and the corrective action. This structure turns search-engine knowledge into measurable SEO execution.